目次
HanDicをKH Coderで利用する
はじめに
立命館大学の樋口耕一先生が開発・公開しておられる,計量テキスト分析のためのフリーソフト「KH Coder」のVer.3にて,HanDicを用いた韓国語の分析が可能になるとのことです.既にアルファ版が公開されているので,実際に韓国語の分析を試してみました.以下の内容は,チュートリアルに従って,韓国語のデータを分析したものです.
準備するもの
特にありません.アルファ版のダウンロードページへ行き,最新のアルファ版をダウンロードしてください.このページの執筆時点(2015年10月16日)で3.0a-03bが公開されています.
なお,Windowsでの使用をおすすめします.MacOSでも使用可能とのことで試してみましたが,設定が大変です.仮想マシンにWindowsをインストールし,そこでKH Coderを利用するのが簡単です.
韓国語を分析するためのHanDicはパッケージに同梱されているため,別途用意する必要はありません.辞書自体はKH Coderのインストールフォルダ内にあるdep/handicフォルダに置かれています.この辞書を差し替えるだけで,新しいバージョンのHanDicを利用することができます.
handicフォルダ内のdicrcに,KH Coderで利用するための設定が追記されているとのことです.
データの準備と読み込み
分析対象のデータを用意し,KH Coderを起動して読み込みます.ここでは韓国の歴代大統領のうち,第16代・盧武鉉,第17代・李明博,第18代・朴槿恵各氏の就任スピーチを使用します.データはHanDicをRとRMeCabで利用すると同じく대통령기록연구실,경향신문の記事から取得し,1行1文に修正したものです.分かち書きの不統一などは手を入れていませんので,厳密には結果に何か影響があるかもしれませんが,とりあえず試みということでご了承ください.
それぞれのテキストを一つのファイルに連結し,各氏のスピーチの前に<h1>16_노무현</h1>,<h1>17_이명박</h1>,<h1>18_박근혜</h1>のような見出しを入れておきます.
<h1>16_노무현</h1> 盧武鉉氏演説内容 … <h1>17_이명박</h1> 李明博氏演説内容 … <h1>18_박근혜</h1> 朴槿恵氏演説内容 …
上記のテキストをUTF-8エンコーディングで保存しておきます.
KH Coderを起動して,「プロジェクト」メニューから「新規」を選択し,「新規プロジェクト」ダイアログで上記ファイルを選択します.また,「言語」に「韓国語」を指定します.「メモ」欄は分析対象の内容などについて記入しておきます.
テキストが読み込まれたら,「前処理」メニューから「前処理の実行」を選択します.
前処理が終了したら,様々な分析を行ってみましょう.
頻出する語の抽出
「ツール」メニューから「抽出語」⇒「抽出語リスト」を実行します.するとオプションを選ぶダイアログが表示されます.ここでは「頻出150語」を選択し,Excelで表示することにしましょう.
上記ダイアログで「OK」を押すと,結果がExcelで表示されます.국민「国民」という語の頻度が最も高くなっています.
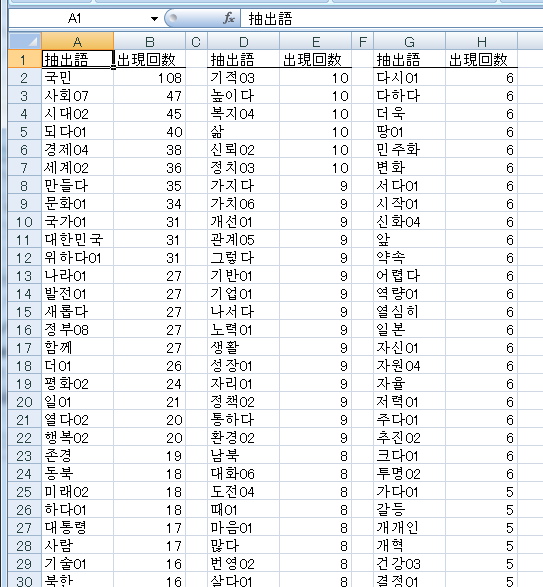
全て基本形にまとめて集計・表示されます.
共起ネットワークの作成
語と語の結びつきを図示する共起ネットワーク図を作成します.「ツール」メニューから,「抽出語」⇒「共起ネットワーク」を選択します.
語と語の結びつき
以下のようなオプションを設定し,「OK」を押します.
結果は以下のようになります.
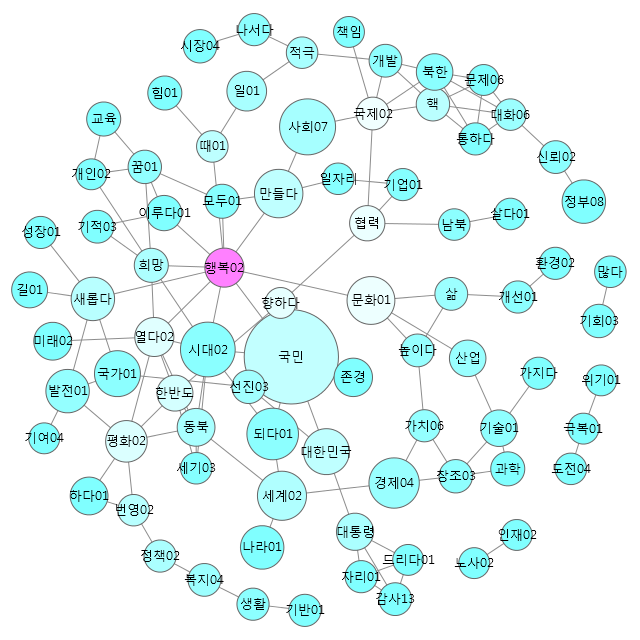
結果表示のウィンドウで「カラー」を「サブグラフ検出(modularity)」とすると,以下のようになったりします.

語と見出しの結びつき
次は,<h1>~</h1>で囲った見出しを元に,共起関係の種類を変更してみます.共起ネットワーク作成のオプションを,以下のように設定します.特に右側,「共起ネットワークの設定」中,「共起関係(edge)の種類」を「語-外部変数・見出し」とし,「外部変数・見出し」を「見出し1」としている点に注意してください.
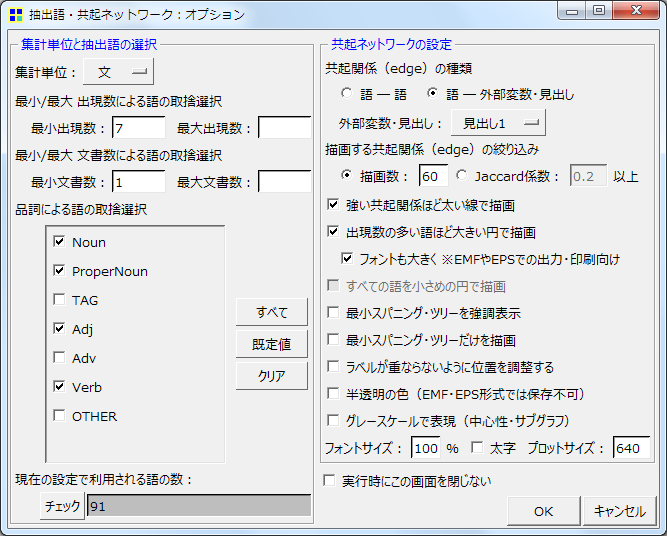
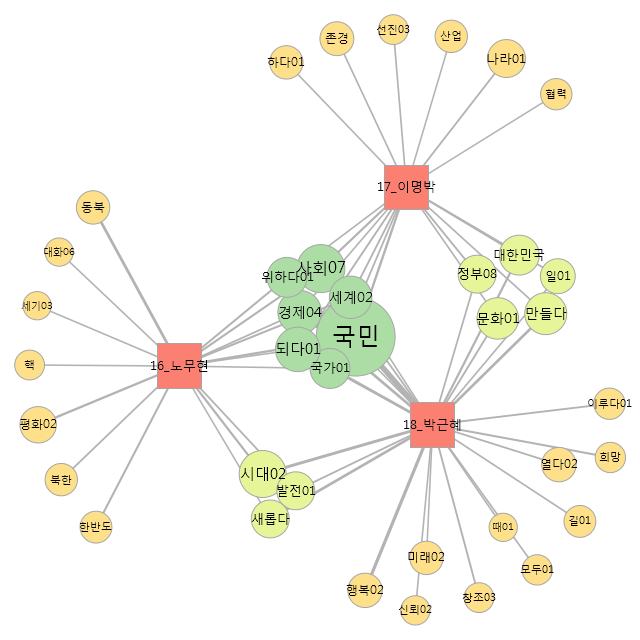
第16代の盧武鉉氏,第17代の李明博氏との間に共通する項目がないのが興味深いです.設定で「描画数」を100に増やしたところ,협력「協力」,하다01「する」が共通項として出て来ました.
各大統領の特徴語抽出
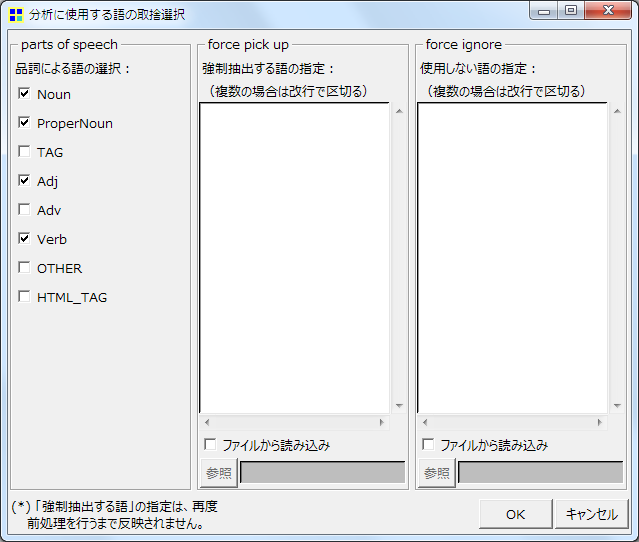
各大統領のスピーチから,それぞれに特徴的な語を取り出してみます.事前の準備として,集計に必要な品詞を指定しておきます.デフォルトのままでは助詞や語尾などもカウントされてしまいます.「前処理」メニューから「語の取捨選択」をクリックし,「品詞による語の選択」を以下のように設定して「OK」を押します.
次に「ツール」メニューから「外部変数と見出し」をクリックします.
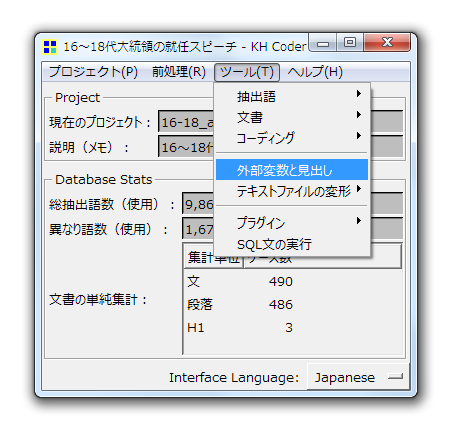
以下の図のように,左列の「変数リスト」に「h1 見出し1」と表示されているはずです.そこをクリックすると,右列に<h1>でマークアップしておいた大統領名が表示されます.右下の「単位」で「文」を選択し,「▽特徴語」から「一覧(Excel形式)」を選択します.
それぞれの大統領のスピーチに特徴的な上位10語が,Excelで表示されます.
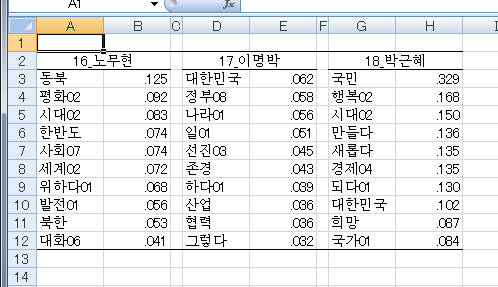
対応分析
対応分析により,各大統領のスピーチに特徴的な語を,視覚的に表示してみます.
「ツール」メニューから「抽出語」⇒「対応分析」をクリックします.現われる設定ダイアログで,以下のように設定を行います.
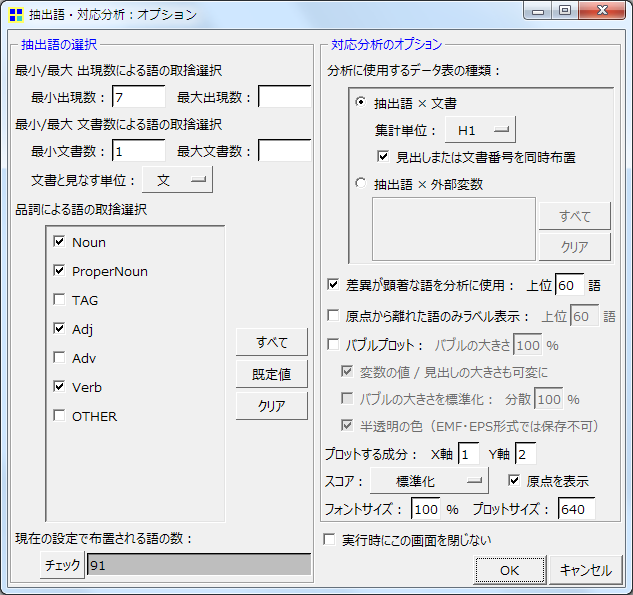
以下のような結果が表示されます.
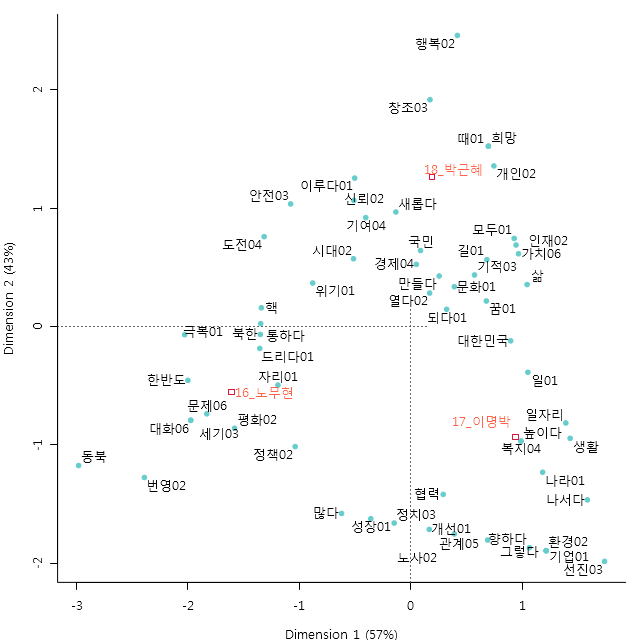
各大統領について原点から最も離れている語を拾うと,盧武鉉氏が동북「東北」,李明博氏が선진03「先進」,朴槿恵氏が행복02「幸福」という結果になりました.「東北」は동북아「北東アジア」が分析された結果と思われます.
メモ
ユーザー辞書の指定
単語の追加方法などで作成したユーザー辞書を追加して使う場合,KH Coderのインストールフォルダ内にあるdep/handic/dicrcの末尾に,ユーザー辞書へのパスを追加します.以下の例は,ユーザー辞書user.dicがE:\00Work\02Data\00kodic\dicにある場合の記述です.
userdic = E:/00Work/02Data/00kodic/dic/user.dic
この設定は,KH Coderで韓国語を解析する場合にのみ適用されます.
抽出する品詞の追加
初期設定では,抽出する品詞が普通名詞,固有名詞,形容詞,副詞,動詞に限られており,それ以外の品詞,例えば助詞や語尾などは「その他」に一括して扱われています.これらを別個に抽出したい場合は,品詞を追加して前処理を行います.
品詞を追加するには,configフォルダ内のhinshi_mecab_kという設定ファイルの末尾に記述を加えます.以下はその例です.
40,JOSA,"Ending-助詞", 41,EOMI,"Ending-語尾",
コンマで区切って記述をしますが,最初の数字は品詞IDで,他と重複しない値を設定します.2列目は品詞名,3列目(条件1)は抽出する条件をHanDicの品詞で記述します.条件2は設定していませんので,コンマで終わります.
Macで使う場合
共起ネットワークに必要なパッケージ
Rの方でigraphパッケージの1.0.1をインストールしていたのですが,描画に失敗しました.CRANのigraphアーカイブからバージョンの0.5.4-4をダウンロードして,~/Desktopに解凍した場合,
install.packages("~/Desktop/igraph/", repos=NULL, type="source")
でインストールします.KH Coderの掲示板を参考にしました.バージョンの0.6以上だと,パッケージインストールの際にgfortran-4.2が無いと言われてインストール出来ませんでした.
新しいバージョンでエラーが出る場合
igraph 1.1.2,ggplot 2.2.1で共起ネットワークを作成する際,
Error: StatEdges was built with an incompatible version of ggproto. Please reinstall the package that provides this extension.
というエラーが出る場合には,ggnetworkをソースからインストールします.
install.packages("ggnetwork", type="source")
対応分析に必要なパッケージ
Rで,maptoolsとade4パッケージをインストールします.
階層的クラスター分析に必要なパッケージ
Rで,ggdendroとamapパッケージをインストールします.
ヒートマップ作成に必要なパッケージ
Rでpheatmapをインストールしますが,CRANのパッケージサイトからArchiveへ進み,バージョン0.7.7をダウンロードして,インストールします.
install.packages("pheatmap_0.7.7.tar.gz", repos=NULL, type="source")
Rから直接最新版をインストールすると,描画に失敗します.
参考文献・リンク
- 樋口耕一(2014)『社会調査のための計量テキスト分析―内容分析の継承と発展を目指して―』,ナカニシヤ出版